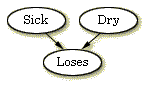 |
| 図 1: アップル・ジャック問題のドメインを表現するBN |
ベイジアンネットワーク (BN) は,不確実性を含むドメインをいくつかの方法でモデルするために用いられる.この不確実性は,ドメインの不完全な理解,所定のタスクを実行するときのドメインのステート(状態)の不完全な知識,ドメインの振る舞いを支配するメカニズムにおける確率性,またはこれらの組み合わせに起因する.
ベイジアンネットワークは,信念ネットワーク(belief networks )とかベイジアン信念ネットワーク(Bayesian belief networks)とも呼ばれる.過去には,因果確率ネットワーク(causal probabilistic networks)という用語も使われてきた.BN は,有向リンクによって接続されたノードのネットワークで,各ノードには確率関数が付属している. BN のネットワーク(グラフ)は,非巡回有向グラフ(DAG:directed acyclic graph)で,すなわち,同じノードに戻ってくる有向パスは存在しない.
ノードは,有限数のステートを持つ離散確率変数または連続(ガウシアン分布)確率変数のいずれかを表現する.このドキュメントでは,"変数”と”ノード”という用語は同じ意味で用いられる.リンクは,ノード間の(因果)関係を表現する.
ノードが親を持たない(すなわち,そのノードに入ってくるリンクがない)場合,そのノードは,周辺確率表を格納する.そのノードが離散の場合,それが表現する変数のステート上の確率分布を格納する.そのノードが連続の場合,それが表現する確率変数のガウシアン密度関数を(平均と分散パラメータを与えて)格納する.
ノードが親を持つ(すなわち,1つまたは複数のリンクがそのノードに入ってくる)場合,そのノードは,条件付き確率表(CPT:conditional probability table)を格納する.そのノードが離散の場合,ノードのCPT(または,より一般的な用語では,条件付き確率関数(CPF:conditional probability function )中の各セルは,その親のステートの特定のコンフィグレーションを仮定した特定のステート中に存在するノードの条件付き確率を格納する.したがって,離散ノードのCPT中のセルの数は,そのノードの可能なステート数と親ノードの可能なステート数の積に等しい.そのノードが連続の場合,その離散親のステートの各コンフィギュレーションの平均と分散のパラメータ,および離散親のステートの各コンフィギュレーションの各連続親の回帰係数を格納する.
下記の事例は,これをより具体的にしようとするものである.
この事例の問題ドメインは,Jack Fletcher(彼をアップル・ジャックと呼ぼう)が所有する小さなリンゴ農園である.ある日,アップル・ジャックは,彼の最高のリンゴの木が葉を失くしていることに気づいた.そこで,彼はなぜこんなことが起きているのかを知りたく思った.彼は,(日照りによって)もし木が乾いているのなら,それは不思議ではないということを知っている.日照りで木の葉がなくなるのは,とても普通のことである.一方,葉を失くすことは,病気を示しているかもしれない.
このシチュエーション(状況)は,図1のようなBNでモデルされる.このBNは3つのノードからなる:Sick(病気),Dry(乾燥),Loses(落葉).これらはすべて2つの状態のうちの1つの状態をとる:Sick は "sick" または "not"のどちらか - Dry は"dry" または "not" のどちらか- Loses は "yes" または"no"のどちらか.ノードSickは,ステート"sick"にあることによってリンゴの木が病気であることを知らせる.それ以外は,ステート"not"である.ノードDry とLoses は,同様に,木が乾燥しているか,木が葉を失くしているかをそれぞれ知らせる.
|
| 図 1: アップル・ジャック問題のドメインを表現するBN |
図1のBNは,SickからLosesへと Dry からLosesへの因果依存性があることをモデルしている.これは2つの矢印で表現されている.
あるノードA から別のノードBへ因果依存性がある場合, Aがある確かな状態(ステート)にあるとき,これはBの状態(ステート)に影響を持つことが期待される.BNで因果依存性をモデルするとき注意深くなければならない.ときどき,どの方向の矢印を持つべきなのかがはっきりしない.たとえば,我々の事例では,木が病気であるとき,その葉が落ちるということが木に起きるであろうから,我々は SickからLosesへの因果の矢印があると言う.しかし,木がその葉を失くすとき,それは病気かも知れないので,矢印は向きを変えるだろうか? いや,それはできない!葉を失くす原因が病気であって,葉を失くすことが病気の原因ではない.
図1で,我々はBNのグラフィカル表現を見た.しかしながら,これは我々がBNの質的表現と呼ぶことだけである.我々がこれをBNと呼ぶには,量的表現を指定する必要がある.
BNの質的表現は,ノードのCPTの集合である.表1,表2,表3 は,図1のBNの3つのノードのCPTを示す.
|
||||
| 表 1: P(Sick). |
|
||||
| 表 2: P(Dry). |
|
|||||||||||||||||||
| 表3: P(Loses | Sick, Dry). | |||||||||||||||||||
3つの表はすべて,ノードがその親ノードのステートによって,特定のステートにある確率を示すが,Sick と Dryは親ノードを持たないので,表1と表2はどのようにも条件付けされないことに留意せよ.
上記のような所定のインスタンスで変数間の因果関係に関与するBNは,静的ベイジアンネットワーク(SBN:Static Bayesian Networks )としても知られる.SBNは,現在のシチュエーションでのみ関与し,時系列を明確にモデルしない. すなわち,過去は無視され,未来は予測されない.たとえば,図2には, 異なる症状を引き起こしうる2つの病気(D1とD2)がある.症状の側の情報を用いて,各病気の確率を予測できる.
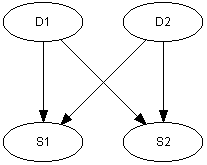 |
| 図 2: 静的ベイジアンネットワーク(SBN)の事例 |
上記で検討した医療のシチュエーションのような多くの問題ドメインでは,物事が時間とともに展開するので,時間次元を用いることなしにデータを表現し,推論することはほとんど考えられないことである.図2で表現するようなSBNは,そのようなシステムでは使用できず,ネットワークは時間的情報を含むように拡張されなければならない.このようなネットワークは,動的ベイジアンネットワーク(DBN:Dynamic Bayesian Networks)として知られる.SBNをDBNに拡張するもっとも簡単な方法は,SBNの複合インスタンス(タイム・スライス)を含み,それらをお互いにリンクさせることである.たとえば,図3のネットワークは,図2のネットワークの複合インスタンスのリンクによって得られる.
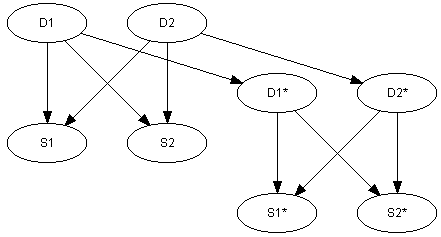 |
| 図 3:動的ベイジアンネットワーク(DBN)の事例 |
今日の疾患の存在は,その疾患が明日存在するかどうかに影響を持つだろう.したがって,"disease today(今日の疾患)" を表現するノード(ノード D1 とD2) と"disease tomorrow(明日の疾患)"を表現するノード (nodes D1* と D2*)の間にリンクを張るべきである.この新しいネットワークを用いて,疾患の進捗を予測することができる..
上記の事例で示したことは,とても簡単なBNの構築方法の説明である.我々がネットワークを構築し終わると,我々は,ステート(状態)が既知であるノードのいくつかにエビデンスを入力するために,それを使用することができ,そして,このエビデンスを仮定して他のノードで計算された新しい確率を回収することができる. リンゴの木の事例は, 我々が木の葉がなくなっているのを知っていると仮定している.そして,我々は, ノードでステート"yes"を選択してこのエビデンスを入力する.そして,我々は, ノードSickが "sick"のステートにある確率で木が病気である確率を読み,ノードDryが"dry"のステートにある確率で木が乾いている確率を読むことができる.上記のようなシチュエーションで,いくつかのエビデンスを仮定して他の変数の確率を計算することは,信念(確信度)の更新(Belief Updating) として知られる.興味のあるもう1つの情報の欠片は,いくつかのエビデンスを仮定したときの,すべての確率変数の最も可能性の高いステートの全体的割り当てである.これは, 信念(確信度)の修正(Belief Revision)として知られる.
Huginは,このようなネットワークの構築のためのツールを提供する.BNを構築したあと,確信度の修正,確信度の更新,その他のことができる.Hugin 開発環境について勉強中のユーザーは, BNの構築方法 のチュートリアルを推奨する.ここで,Hugin グラフィカル・ユーザー・インタフェースを用いて,リンゴの木の BN が構築される.またオブジェクト指向ネットワークへの入門も読むことを推奨する; たとえば,オブジェクト指向ネットワークは,上記の疾患ネットワークのような反復構造を持つネットワークを構築するときにとても強力である.あるいは,インフルエンス・ダイアグラム(ID)への入門に読み進むこともできる.IDは,効用ノードと決定ノードで拡張されたBNである.
正式には,ベイジアンネットワークは下記のように定義される:
定義 ベイジアンネットワークとは,ペア (G,P)である.ここで, G=(V,E) は,有向リンク(またはエッジ)E によって相互接続されたノードの有限集合Vの有向非巡回グラフ(DAG:directed acyclic graph )で,Pは,(条件付き)確率分布の集合である.ネットワークは以下のプロパティを持つ:
![]()
ノードは確率変数を表現し,リンクは変数間の確率的従属性を表現する.これらの従属性は,条件付き確率表(CPT)の集合を用いて定量化される: 各変数は,その親を仮定した変数のCPTを割り当てられている.親を持たない変数については,無条件(または周辺)分布である.
ベイジアンネットワークの最も重要なコンセプトは,条件付き独立(conditional independence)である.変数Cの値がわかっていて,変数Bの値に関する知識が,変数A の値に関して,それ以上の情報を提供しない場合,変数A と B の2つの集合は,変数の第3の集合C を仮定して,(条件付きで)独立であると言える:
![]()
条件付き独立は,下記のようにグラフから直接読み取れる: A, B, C が,変数の互いに素な集合とすると,
ここで, A の中のある変数からB の中のある変数へのすべてのパスが,Cの中の変数を含む場合,A は, C を仮定して,Bの条件付き独立である (Lauritzen et al. 1990).
このコンセプトを説明するために,以下に架空の医療知識の断片を考える:
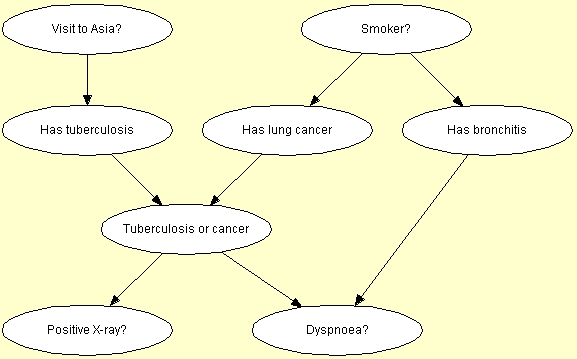
| "呼吸困難 (dyspnoea) [d] は, 結核(tuberculosis) [t], 肺がん(lung cancer) [l], 気管支炎(bronchitis) [b]に起因するかもしれないし,またこれらには起因しないかもしれない.最近のアジアへの訪問(visit to Asia) [a] は,結核(tuberculosis)のリスクを高める,一方,喫煙(smoking) [s] は,肺がん(lung cancer)と気管支炎(bronchitis)の両方のリスク要因であることが知られている.呼吸困難(dyspnoea)の有無なしに,胸部レントゲンの結果(X-ray) [x] だけでは,肺がん(lung cancer)と結核(tuberculosis)を判別できない." (Lauritzen & Spiegelhalter 1988). |
最後の事実は,グラフ中の中間変数 eで表現される.この変数は, その2つの親 (t と l)のlogical-orである; これは,一方の疾患,または,両方の疾患,または,両方とも非疾患の存在を要約する.
図 4 は,この知識のモデルを示す.
 |
|
図 4: 肺がんに関与する医療知識の構造的側面を表現するグラフ |
もし患者が喫煙者(smoker)であるとわかった場合,我々は肺がん(lung cancer) と気管支炎(bronchitis)に関する信念(リスクの増大)を調整する.しかしながら, 結核(tuberculosis)に関する信念は変わらない(すなわち, t は,変数の空集合を仮定して, s の条件付き独立である).今度は,患者のレントゲン ( X-ray )の結果が陽性だったと仮定する.これは,結核(tuberculosis)と肺がん(lung cancer)に関する我々の信念に影響するが,気管支炎(bronchitis)に関する信念には影響しない(すなわち,b は,sを仮定して xの条件付き独立である).ただし,我々は患者が呼吸困難に苦しんでいることも知っていて, レントゲン(X-ray)の結果は, 気管支炎(bronchitis)に関する我々の信念にも影響する(すなわちb は,s と dを仮定して, x の条件付き独立でない).
これらの(独立)従属性は,上で説明した方法を用いて,図1のグラフからすべて読み取ることができる.
このほか,条件付き独立の決定のための同等な手法は,Pearl (1988)によるd-分離がある.
ベイジアンネットワークでの推論は,他の変数で情報(エビデンス)を仮定して,いくつかの変数の条件付き確率を計算することを意味する.
これは,すべての利用可能なエビデンスが,興味対象の変数の先祖である変数上にある場合は簡単である.しかし,エビデンスが興味対象の変数の子孫上にある場合,我々はエッジの向きと反対に推論を実行しなければならない.この目的を達成するために,我々はベイズの定理を採用する:
![]()
Huginの推論は,本質的に,ベイズの定理の巧妙な応用である; 詳細は, Jensen 等 (1990(1))の論文にある.
Hugin Decision Engine は,離散確率変数と連続確率変数の両方を持つネットワークを取り扱うことができる.連続確率変数は,親の値を条件とするガウシアン(正規)分布を持たなければならない.
離散親 I と連続親 Z を持つ連続変数Y の分布は,親の値を条件とした(1次元の)ガウシアン分布である:
![]()
平均は連続親変数に線形的に従属し,分散は連続親変数に従属しないことに注意せよ.ただし,この線形関数と分散の両方は,離散親変数には従属することが可能である・これらの制約が,正確な推論が可能であることを確かにする.
離散変数は,連続親を持つことができないことに注意せよ.
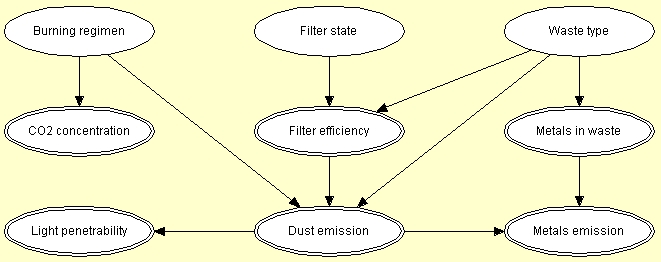
図 5 は,廃棄物焼却炉のネットワーク・モデルを示す (
| "廃棄物焼却炉からの(粉塵や重金属の)排出は,投入される廃棄物 [W] の組成の差異によって異なる.もう1つの重要な要因は,廃棄物の燃焼管理(burning regimen) [B]で,これは排気[C]中のCO2 の濃度を計測してモニタされる.フィルタ効率(filter efficiency) [E] は,電子フィルタの技術的状態(technical state) [F] と廃棄物の量や組成 [W]に従属する.重金属の排出 [Mo] は,一般的に,投入される廃棄物中の金属濃度 [Mi] と 粉塵の微粒子の排出 [D] に従属する. 粉塵の排出 [D] は,光の透過性[L]を計測してモニタされる." |
 |
|
図 5: 廃棄物焼却モデルの構造的側面l: B, F, W は離散変数で,その他は連続変数. |
条件付きガウシアン変数を含むネットワーク・モデル内の推論の結果は, - 常に - エビデンスを仮定した個々の変数の信念(確信度)(すなわち,周辺分布)である.離散変数については,これは,その変数のステートでの確率分布に計量される.条件付きガウシアン変数については,2つの測度が提供される:
図5に示すネットワークから(そして,離散変数 B, F, W はすべてバイナリであるとすると),以下のことがわかる.
Hugin グラフィカル・ユーザー・インタフェースを用いて条件付きガウシアン分布関数を指定する方法の詳細は,ガウシアン分布関数 を参照せよ.
Hugin グラフィカル・ユーザー・インタフェースを用いてベイジアンネットワークを構築する方法は,BNの構築方法 のチュートリアルを参照せよ.
翻訳者:多田くにひろ(マインドウェア総研)