Mindware Research Institute provides the following solutions based on over 25 years of experience in the fields of statistics and data science.
Concept Generator
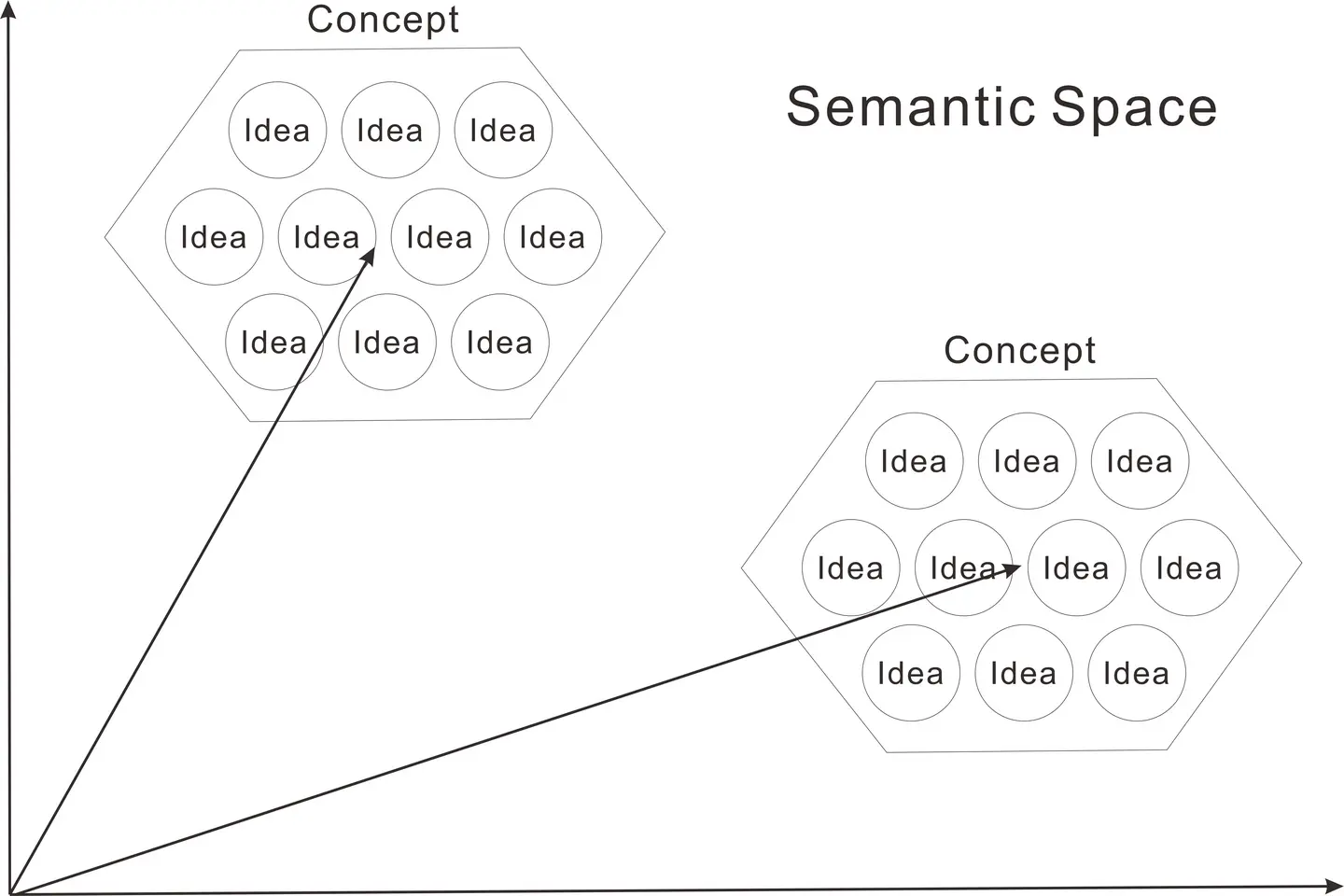
It is now common knowledge to use LLM to generate ideas or scraype huge amount of information from the net, but a new problem is how to evaluate them. Mindware Research Institute proposes grouping many ideas based on their similarities. This grouping is called a “concept”. This is because in philosophy and logic, a concept is defined as consisting of extension and intention (connotation). In layman’s terms, extension refers to the scope of a group, and intension refers to common characteristics within a group.
No matter how innovative an idea may be, developing a business based on inconsistent and disparate ideas is a bad move from a strategic perspective. In the past, this could only be determined using a linguistic sense, but a major change in recent years in cutting-edge data science is that it has become possible to calculate ideas and concepts by converting them into vector quantities. Grouping ideas in a semantic space using vector computations provides the following benefits:
- Strategic idea evaluation: By clearly defining the conceptual differences between ideas and groups through LLM, you can accurately judge which areas your company should work on from the dimensions of business philosophy and business strategy.
- Creation and fine-tuning of additional ideas: Based on the positional relationship of a large number of existing ideas mapped in semantic space, LLM can accurately predict the content of unknown ideas located in the middle or outside of them.
Similarity Search in RDB
Similarity search becomes possible by using LLM and Embedding Vectors. For this reason, major vendors are trying to sell products called “vector databases” that are different from widely popular RDBs (relational databases). Mindware Research Institute provides technology that enables similar searches using conventional RDB. Divide the semantic space into small local spaces and assign nodes to each of them. This is possible by creating a table in the RDB that defines the proximity relationship between the nodes.

Multimodal Information Processing
The use of Embedding Vectors which key of LLMs, is not limited to text information, but is increasingly becoming multimodal, including audio and images. This means you can search for images with text and categorize contents that combines text, audio, and images. At Mindware Research Institute, we take a different approach than major vendors and make this easier. By using our unique self-organizing competitive learning, we learn the entire multimodal data and place each case in the semantic space (Semantic Space Model). For example, even if the new data is text-only, you can search for similar multimodal content by matching just the text elements of the Semantic Space Model. Sentiment analysis is also possible as an application of this technology.
Unlabeled Data Learning
Creating labeled training data is a bottleneck in current AI and machine learning projects. It is difficult to achieve better results when using low-quality training data from outsourced labeling tasks. Therefore, Mindware Research Institute proposes the effective use of unsupervised learning to avoid this problem. Honestly, you can’t replace every project with this, but by carefully redefining “What do we want in the end?” the segmentation models you get from unsupervised learning can often be effective.
Synthetic Data Creation
Today, data utilization such as statistics and data science are indispensable in order to incorporate a scientific approach into business. However, the data that can be realistically used only represents the present or past, and there is very little data that represents the future. Ther is a dilemma that the more you try to utilize data in your business, the more you end up looking at the past instead of the future. Especially when new markets are being created through technological innovation, there is no data on future markets. In order for a company to formulate a strategy in such a situation, it is necessary to create a blueprint for the future that can be extrapolated as much as possible from the currently available information. Data synthesis techniques provide a solution to this problem.