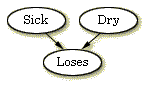 |
| 図 1: BN入門で構築したBN |
(制限記憶)インフルエンス・ダイアグラム(ID)は,さまざまな決定の代案とそれらに関連する効用を明確にモデルしたい場合,ベイジアンネットワークの代わりに使用できる.ある程度は,純粋なBNでも意思決定のモデルを構築することができるが,効用と決定のコンセプトが明確にはカバーされていない.インフルエンス・ダイアグラムとは,効用ノードと決定ノードで拡張されたBNのことである.これらの新しい2つのタイプのノードを持つことにより,我々は古いタイプのノードにも名前が必要となる.我々はこれらのノードを確率ノード(chance node)と呼ぶことにしよう.
BN入門のリンゴの木の事例で構築したBNを拡張して,インフルエンス・ダイアグラムのコンセプトを説明する.
我々は,再びリンゴの木の事例を考える(図1).
|
| 図 1: BN入門で構築したBN |
Apple Jack は,ここで木の手入れのために資源を投資するかどうかを決定したいのである. これは時系列での決定を伴うので,BN入門の節で説明したように,BNを動的なものに修正しなければならない.まず我々は,すでにネットワーク内のノードととてもよく似た3つのノードを追加する.新しいノード Sick', Dry', Loses' は,それらが収穫時のシチュエーションを表現していることを除いては,古いノードと同じことを表現する.図2にこれらのノードが追加された.
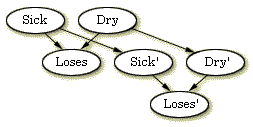 |
| 図 2: 木のステートの収穫時の期待を表現する類似ノードの追加 |
新しいノードは,古いノードと同じステートにあることができる: Sick' は "sick" か "not" のいずれか- Dry' は "dry" か "not" のいずれか- Loses' は "yes" か "no"のいずれかである.新しいモデルでは,我々は 古い Sick ノードから新しい Sick' ノードへと,古い Dry ノードから新しいDry' ノードへの因果依存性を予想する.これは,たとえば,木が現在病気であるなら,将来もそうだろうと予想されるからである.もちろん,依存性の強さは,どれぐらい遠い未来に我々が見るかによる.たぶん,Loses から Loses' への依存性もあり得るが,我々はこのモデルではそうはしない.
Apple Jackは,彼の問題について何かを行う機会を持つ. 彼は考えられる病気を取り除くための治療を木に施そうとすることができる.葉の喪失が日照りによるものと彼が考えるなら,彼は金を節約して,ただ雨を待つだけだろう.ここで,木を治療するアクションが決定ノードとしてBNに追加され,もはやBN[ではなくなる.図3に示すインフルエンス・ダイアグラムとなる.アクション・ノードは,四角形で表現される.
 |
| 図 3: 治療のための決定ノードの追加. |
治療の決定ノードは,ステート "treat" および "not"を持つ.図3にあるように,我々はTreat から Sick'へのリンクを追加した.これは,我々が治療が木の未来の健康に影響を持つことを期待するからである.
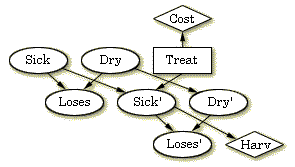
インフルエンス・ダイアグラムが完成される前に,我々は決定の期待効用を計算することを可能にする効用関数を指定する必要がある.これはダイアグラムに効用ノードを追加して行われる.各効用は合計効用の一部に寄与する.効用ノードは図4のように追加される.効用ノードはひし形で表現する.
 |
|
図 4: Apple Jackの果樹園での意思決定に使用されるインフルエンス・ダイアグラムの完成した質的表現 |
効用ノード Cost は,治療のコストに関する情報を集め,一方,Harv は収穫時の効用を表現する.それは,リンゴの生産が木の健康に依存することを示すSick' のステートに依存する.
図 4 は,インフルエンス・ダイアグラムの完成した質的表現を示す.量的表現も得るには,各確率ノードに条件付き確率表(CPT)を,そして各効用ノードに効用表を構築する必要がある.決定ノードには表は必要ない.
以下の表は,確率ノードのCPTがどのように指定できるかの1つの方法を示す.
|
||||
| 表 1: P(Sick). |
|
||||
| 表 2: P(Dry). |
|
|||||||||||||||||||
| 表 3: P(Loses | Sick, Dry). | |||||||||||||||||||
|
|||||||||||||||||||
| 表 4: P(Sick' | Sick, Treat). | |||||||||||||||||||
|
|||||||||
| 表 5: P(Dry' | Dry). |
|
|||||||||||||||||||
| 表 6: P(Loses' | Sick', Dry'). | |||||||||||||||||||
以下の表は,効用ノードの表を米ドル(金額)で指定している.
|
||||
| 表 7: U(Harv). |
|
||||
| 表 8: U(Cost). |
効用表は,単純なコスト関数である.表 7 は,もし我々が健康な木を持つ(Sick' のステートが "not")なら,Apple Jackは $20000の収入を得る. 一方,木が病気(Sick' のステートが "yes")なら Apple Jackの収入は $3000だけになる.表 8 は,木を治療するために Apple Jack が $8000かけることを示す.我々のインフルエンス・ダイアグアムの目的は,最高の期待効用を得るTreat ノードのアクションを計算できるようにすることである.もしコンピュータの助けなしでこれをやるとすると,これはかなり用心の必要な仕事である.我々は, ここでHuginグラフィカル・ユーザー・インタフェース内でインフルエンス・ダイアグラムを実装して計算をさせる方法を説明する 2つのチュートリアルを通して試行することを推奨する.以下は, (制限記憶)インフルエンス・ダイアグラムの意味と,それらの活用上強いられる関連した制約についてより深く説明する.
インフルエンス・ダイアグラムと は,決定ノードと効用ノードで拡張されたベイジアンネットワークである(インフルエンス・ダイアグラムのrandom variablesは,しばしばchance variablesと呼ばれる.訳語は共に「確率変数」とすることとする).決定ノードへのリンクは時間順位を示す.確率変数から決定変数へのリンクは,決定がなされるときには確率変数の値がわかっていることを示す.そして,1つの決定変数からもう1つの決定変数へのリンクは,対応する決定の時間的順序を示す. ネットワークは非巡回でなければならず,ネットワーク中のすべての決定ノードを含む有向パスが存在しなければならない.
我々は,このアプリケーションで最善の可能な決定をなすことに興味がある.したがって,我々は,効用をネットワークのステート・コンフィギュレーションに関連づける.これらの効用は,効用ノードで表現される.各効用ノードは,その親のステートの各コンフィギュレーションに効用を関連づける効用関数を持つ(効用ノードは子を持たない). 決定をなすことにより,ネットワークのコンフィギュレーションの確率に影響を与える.したがって,我々は,各決定代案の期待効用を計算することができる(全体の効用関数は,すべてのローカルな効用関数の総和である).我々は最高の期待効用を持つ代案を選ぶ:これは,最大期待効用原理または期待効用最大化原理(maximum expected utility principle)として知られている.
従来のインフルエンス・ダイアグラムと比較してLIMIDの意味では,非忘却の仮定と決定の完全な順序の緩和が重要な変更を含意する. LIMID では,決定の時点で意思決定者が利用可能な情報を,各決定ごとに指定することが不可欠である. LIMIDでは暗黙な情報リンクはない.決定ノードへのリンクは,決定時に親ノードの値が既知であることを指定する.
HUGIN Decision Engine での制限記憶インフルエンス・ダイアグラムの実装に内在する計算手法は,Lauritzen & Nilsson (2001)に説明されている. 使用されているアルゴリズムは, 単一ポリシー更新(Single Policy Updating)として知られている.
もう1つの事例として,以下の決定シナリオを考える:
|
石油試掘者は掘削を行うかどうかを決定しなければならない.彼は穴がdry なのか wet なのか,または soaking なのか確かでない.$10,000のコストで, 石油試掘者は,現場の隠れた地質構造を決定することを支援する地震探査を実施できる.地震探査は,下部の地形が,closed structure (良い)か,open structure (まあまあ)か,またはno structure (悪い)のかを明らかにする. |
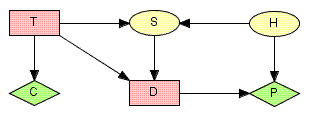
この意思決定シナリオは,図 5 のインフルエンス・ダイアグラムによって表現でき,ここで T は試験をするかしないかの決定を表し; D は掘削をするかしないかの決定を表し; S は(石油試掘者が試験をすると決定した場合の)地震探査の結果を表し; H は穴の状態を表し; C は地震探査に関わるコストを表し; そして P は,掘削に関わる期待利益を表す.
 |
|
図 5: 石油試掘者の意思決定問題のインフルエンス・ダイアグラム |
掘削のコストは,$70,000である.石油試掘者が掘削をすると決定した場合,期待利益 (すなわち,石油発見の価値マイナス掘削のコスト)は,穴がのdry場合$-70,000,穴がwet の場合$50,000,穴がのsoaking場合$200,000であり,石油試掘者が掘削をしないと決定した場合,利益は(もちろん) $0である.
専門家は,穴の状態について,次の確率分布を推定した: P(dry)=0.5, P(wet)=0.3, and P(soaking)=0.2. さらに,地震探査試験は完全ではない; 穴の状態を仮定した試験の結果の条件付き確率は:
|
このインフルエンス・ダイアグラムに基づいて, Hugin Decision Engine は,試験をする場合の効用が $22,500 であり,試験をしない倍の効用が $20,000であることを計算する.そして,最適な戦略は,地震探査試験を実行して,試験の結果に基づいて掘削を行うかどうかを決定することである.
ノードT からノード D への情報リンクの風変わりな影響に注意せよ.LIMIDは,従来のインフルエンス・ダイアグラムの非忘却仮定を緩和する.これは,各決定ノードでは,意思決定者にとって利用可能な情報を正確に指定することが不可欠(でかつとても重要)であることを含意する.ネットワーク中に存在する暗黙的な情報リンクを仮定しない.
[この事例は Raiffa (1968)による.この事例のより詳しい説明は, 事例 の節にある.]
図4のLIMID は,決定に先立って観察がなされない単一の決定を仮定するApple Jack問題を表現する. より現実的な設定では, Apple Jack は,日ごととか,一定の期間で木を監視するであろう. 彼は木の処理に関する検定をなす前に,木が葉を落としているかどうかを観察すると仮定しよう.日々,彼は, 前日にどうしたかに関わりなく,木が葉を落としているかどうかを見て,処理に関する決定を行う.我々は,この状況をモデルするために,制限記憶インフルエンス・ダイアグラム(LIMID: limited memory influence diagram)を使用することができる.
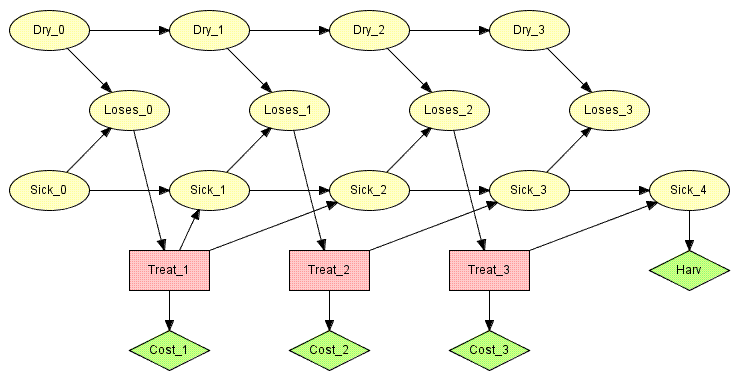 |
図 6: 複数の決定を持つApple Jack の制限記憶インフルエンス・ダイアグラム. |
図 6 は,収穫前の3日間Apple Jack が木を監視する前述の状況での制限記憶インフルエンス・ダイアグラムを示す.ダイアグラムの情報リンクは, Apple Jack は木が(まだ)葉を落としているかどうかを毎日観察するが,前の時間ステップでの観察も決定も想起しないことを指定している.
LIMIDの解は,各決定で1つのポリシー(方策)からなる戦略である.ポリシーは,既知の変数から決定のステートへの関数である.意思決定者が落葉に関する直近の観察(オブザベーション)のみを知っていることを仮定しているので,それは過去のすべての観察の関数ではない.これは,従来のインフルエンス・ダイアグラムが,意思決定者が忘却しないことを仮定していて,ポリシーが過去のすべての観察と決定からの関数であるのとは異なる.
事例では,決定の完全順序がある.これが一般的なケースとは限らない.
Hugin Graphical User Interfaceを用いてインフルエンス・ダイアグラムを構築する方法について学ぶには,LIMIDの構築法 チュートリアルを参照してください.また(制限記憶)インフルエンス・ダイアグラムの意味 やそれらの活用上の制約についても学ぶとよい.
翻訳者:多田くにひろ(マインドウェア総研)